
당신은 주제를 찾고 있습니까 “그로버 알고리즘 – 양자컴퓨터의 기초와 그루버 알고리즘“? 다음 카테고리의 웹사이트 ppa.maxfit.vn 에서 귀하의 모든 질문에 답변해 드립니다: https://ppa.maxfit.vn/blog/. 바로 아래에서 답을 찾을 수 있습니다. 작성자 Saesun Kim 이(가) 작성한 기사에는 조회수 7,921회 및 좋아요 249개 개의 좋아요가 있습니다.
그로버 알고리즘(Grover Algorithm)은 탐색 문제에 관한 기하학적 특성과 양자적 특성을 이용해 고전적 컴퓨터가 지수적인 시간 복잡도로 구현하는 탐색 문제를 다항 시간에 풀수 있도록 한 양자 알고리즘이다.
그로버 알고리즘 주제에 대한 동영상 보기
여기에서 이 주제에 대한 비디오를 시청하십시오. 주의 깊게 살펴보고 읽고 있는 내용에 대한 피드백을 제공하세요!
d여기에서 양자컴퓨터의 기초와 그루버 알고리즘 – 그로버 알고리즘 주제에 대한 세부정보를 참조하세요
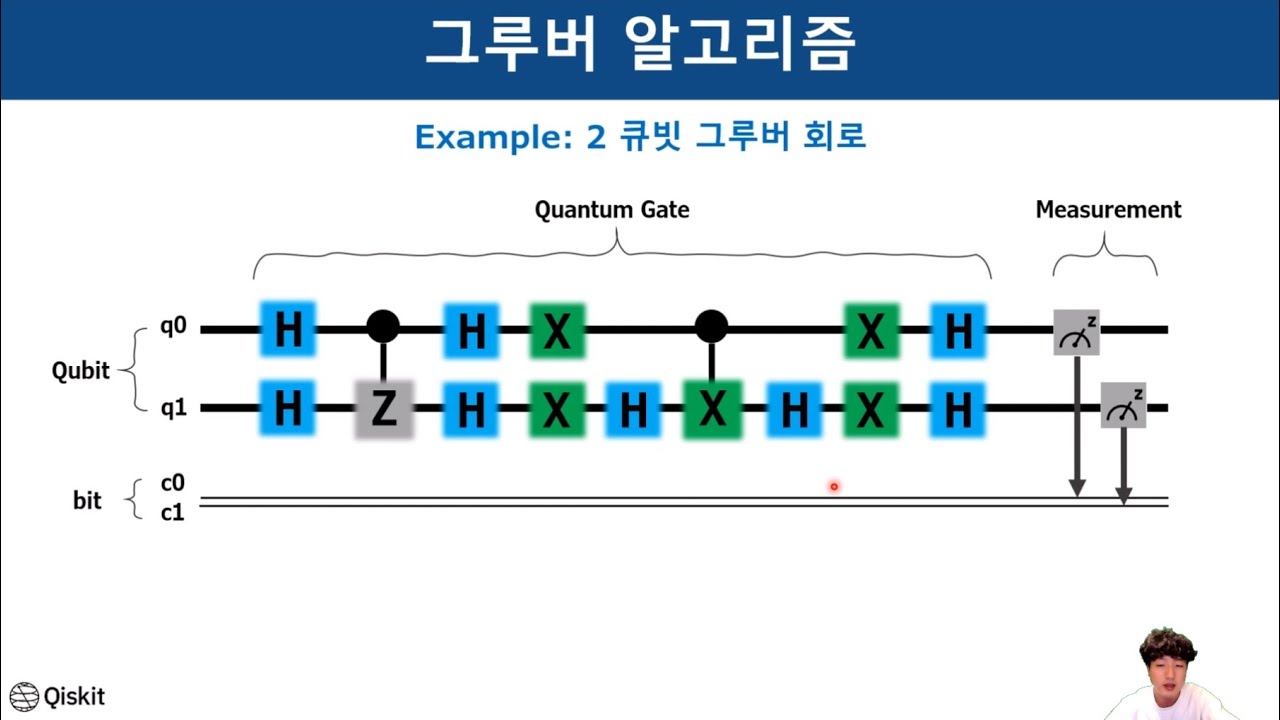
양자컴퓨터의 기본적인 원리와 계산하는 방법에 대해서 이야기 해보겠습니다. 그리고 이러한 개념들을 바탕으로 그르버 알고리즘에 대해서 이야기해보겠습니다.
성균관대학교 양자정보지원센터에 감사드립니다.
00:00 – 소개
00:34 – 일반컴퓨터와 양자컴퓨터의 비교
02:54 – 양자회로: 큐비트
05:21 – 양자회로: X게이트
06:00 – 양자회로: H게이트
07:13 – 양자회로: Z게이트
08:35 – 두개이상의 큐비트
10:05 – 양자회로 CX게이트
11:41 – 양자회로 CZ게이트
12:20 – 양자회로 CCX게이트
12:20 – 양자회로 NOT 게이트
14:30 – 양자회로 AND 게이트
15:10 – 양자회로 OR 게이트
16:11 – 양자회로 더하기
18:17 – 양자회로 비용 계산하기
20:42 – 그루버 알고리즘
22:13 – 그루버 알고리즘 중첩
23:35 – 확률진폭그래프
24:30 – 백터그래프
25:46 – 그루버 알고리즘 오라클
28:42 – 그루버 알고리즘 디퓨져
30:49 – 두개의 큐비트로 만든 그루버 알고리즘
36:41 – IBM 양자컴퓨터 연산
37:15 – 그루버 알고리즘 반복연산
38:46 – 그루버 알고리즘 한계
40:05 – 끝내는 말
그로버 알고리즘 주제에 대한 자세한 내용은 여기를 참조하세요.
Grover의 검색 알고리즘의 이론 – Azure Quantum
이 문서에서는 Grover의 알고리즘이 작동하도록 하는 수학적 원리에 대해 자세히 설명합니다. 수학적 문제를 해결하는 Grover 알고리즘의 실용적인 …
Source: docs.microsoft.com
Date Published: 3/25/2021
View: 6765
[양자컴퓨터 기초 이론] 5. 그로버 알고리즘과 도이치 알고리즘
그로버 알고리즘과 도이치 알고리즘. 오라클, 확률증폭, Grover’s Algorithm과 Deutsch’s Algorithm. 8 minute read. image. Basic of Quantum Computer( …
Source: hgmin1159.github.io
Date Published: 1/10/2022
View: 9342
양자 알고리즘의 세계 – 과학의 지평
이 놀라운 사실은 그로버Lov Grover의 알고리즘으로 알려져 있다.[6] 1990년대 벨 연구소에서 일하고 있던 그로버는 쇼어의 소인수 분해 알고리즘에 …
Source: horizon.kias.re.kr
Date Published: 5/28/2022
View: 5919
[ 양자 알고리즘 ] 쇼어(Shor) , 그로브(Grove) 알고리즘 개념 및 …
그로버(Grover) 알고리즘은 쇼어(shor)알고리즘이 등장한 후 2년뒤, 1996년에 인도계 미국 컴퓨터공학자였던 롭 그로버(Lov Grover)에 의해 고안된 개념 …
Source: m.blog.naver.com
Date Published: 5/22/2022
View: 5856
그로버 알고리즘(Grover’s algorithm)
qiskit 문서 ‘Grover’s search with an unknown number of solutions’를 참고하였고 그로버 알고리즘의 통계학적 해석에 대해서는 통계학 교수님께 …
Source: luvquantum91.tistory.com
Date Published: 12/3/2022
View: 6349
양자 컴퓨팅 입문 (2) – Grover’s Algorithm
Grover’s Algorithm은 정렬되지 않은 데이터베이스에 있는 $N$개의 항목 중 특정한 조건을 만족하는 항목을 $O(\sqrt{N})$에 찾는 알고리즘입니다.
Source: www.secmem.org
Date Published: 8/25/2022
View: 5111
그로버의 알고리즘 – wiko
에서는 양자 컴퓨팅 , 그로버 알고리즘 일컬어, 양자 됨 알고리즘 하는 지칭 양자 알고리즘 구조적 검색 것을 발견 높은 확률로 (A)에 고유 한 입력 블랙 박스 불과 …
Source: wiko.wiki
Date Published: 5/21/2021
View: 9084
주제와 관련된 이미지 그로버 알고리즘
주제와 관련된 더 많은 사진을 참조하십시오 양자컴퓨터의 기초와 그루버 알고리즘. 댓글에서 더 많은 관련 이미지를 보거나 필요한 경우 더 많은 관련 기사를 볼 수 있습니다.
주제에 대한 기사 평가 그로버 알고리즘
- Author: Saesun Kim
- Views: 조회수 7,921회
- Likes: 좋아요 249개
- Date Published: 2020. 11. 24.
- Video Url link: https://www.youtube.com/watch?v=EuAjgGHqJ5A
Grover의 검색 알고리즘의 이론 – Azure Quantum
목차
Grover의 검색 알고리즘의 이론
아티클
07/12/2022
읽는 데 13분 걸림
기여자 6명
이 문서의 내용
이 문서에서는 Grover의 알고리즘이 작동하도록 하는 수학적 원리에 대해 자세히 설명합니다.
수학적 문제를 해결하는 Grover 알고리즘의 실용적인 구현을 위해 Grover의 검색 알고리즘을 구현하기 위한 가이드를 참조할 수 있습니다.
문제의 설명
모든 검색 작업은 검색 항목 $x$를 허용하는 추상 함수 $f(x)$로 표현할 수 있습니다. 항목 $x$가 검색 작업의 솔루션인 경우 $f(x)=1$입니다. $x$ 항목이 솔루션이 아니면 $f(x)=0$입니다. 검색 문제는 $f(x_0)=1$과 같은 $x_0$ 항목을 찾는 것으로 구성됩니다.
Grover의 알고리즘이 해결하려는 작업은 다음과 같이 표현할 수 있습니다. 주어진 클래식 함수 $f(x):\{0,1\}^n \rightarrow\{0,1\}$, 여기서 $n$은 검색 공간의 비트 크기입니다. $f(x_0)=1$에 해당하는 입력 $x_0$을 찾습니다. 알고리즘의 복잡성은 $f(x)$ 함수 사용의 횟수로 측정됩니다. 일반적으로 최악의 시나리오에서 $N=2^n$인 경우 $f(x)$를 총 $N-1$번 평가해야 합니다. 모든 가능성을 시험해보세요. $N-1$ 요소 다음에는 마지막 요소여야 합니다. Grover의 양자 알고리즘은 이 문제를 훨씬 빠르게 해결할 수 있으므로 2차 속도를 제공합니다. 여기서 2차는 N에 비해 약 $\sqrt{$N$}$개의 평가만 필요하다는 것을 의미합니다.
알고리즘 개요
검색 작업에 적합한 항목이 $N=2^n$개 있고 각 항목에 $0$에서 $N-1$까지의 정수를 할당하여 인덱스된다고 가정합니다. 또한 $M$개의 서로 다른 유효한 입력이 있다고 가정합니다. 이는 $f(x)=1$에 해당하는 $M$개의 입력이 있음을 의미합니다. 알고리즘의 단계는 다음과 같습니다.
$\ket{0}$ 상태에서 초기화된 $n$개 큐비트의 레지스터로 시작합니다. 레지스터의 각 큐비트에 $H$를 적용하여 레지스터를 균일한 중첩으로 준비합니다. $$|\text{register}\rangle=\frac{1}{\sqrt{N}}\sum_{x=0}^{N-1}|x\rangle$$ 다음 연산을 레지스터 $N_{\text{optimal}}$ 시간에 적용합니다. 솔루션 항목에 대해 $-1$의 조건부 위상 편이를 적용하는 위상 oracle $O_f$. 레지스터의 각 큐비트에 $H$ 적용. $\ket{0}$을 제외한 모든 계산 기반 상태로 $-1$의 조건부 위상 편이. $O_0$은 $\ket{0}$으로만 조건부 위상 편이를 나타내므로 유니터리 연산 $-O_0$으로 나타낼 수 있습니다. 레지스터의 각 큐비트에 $H$ 적용. 확률이 매우 높은 솔루션인 항목의 인덱스를 가져오려면 레지스터를 측정합니다. 유효한 솔루션인지 확인합니다. 그렇지 않은 경우 다시 시작합니다.
$N_\text{optimal}=\left\lfloor \frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{1}{{2}\right\rfloor$는 레지스터를 측정하여 올바른 항목을 얻을 가능성을 최대화하는 최적의 반복 횟수입니다.
참고 3.b, 3.c 및 3.d 단계의 공동 적용은 일반적으로 문헌에서 Grover의 확산 연산자로 알려져 있습니다.
레지스터에 적용되는 전체 유니터리 연산은 다음과 같습니다.
$$(-H^{\otimes n}O_0H^{\otimes n}O_f)^{N_{\text{optimal}}}H^{\otimes n}$$
레지스터의 상태를 단계별로 수행합니다.
프로세스를 설명하기 위해 큐비트가 2개뿐이고 유효한 요소가 $\ket{01}인 간단한 경우에 대해 레지스터 상태의 수학적 변환을 수행해 보겠습니다.$
레지스터는 state: $$|\text{register}\rangle=|00\rangle$$에서 시작합니다. 각 큐비트에 $H$를 적용하면 레지스터의 상태가 다음으로 변환됩니다. $$|\text{register}\rangle=\frac{{1}{\sqrt{{4}}\sum_{i \in \{0,1\}^2}|i\rangle=\frac12(\ket{00}+\ket{01}+\ket{10}+\ket{11})$$ 그런 다음, 위상 oracle이 get: $$|\text{register}\rangle=\frac12(\ket{{00}-\ket{{01}+\ket{{10}+\ket{{11})$$에 적용됩니다. 그런 다음 $H$는 각 큐비트에 대해 다시 작동하여 다음을 제공합니다. $$|\text{register}\rangle=\frac12(\ket{{00}+\ket{{01}-\ket{{10}+\ket{{11})$$ 이제 조건부 위상 편이가 $\ket{00}$: $$|\text{register}\rangle=\frac12(\ket{{00}-\ket{{01}+\ket{{10}-\ket{{11})$$를 제외한 모든 상태에 적용됩니다. 마지막으로 첫 번째 Grover 반복은 $H$를 다시 get: $$|\text{register}\rangle=\ket{{01}$$에 적용함으로써 끝납니다. 위의 단계를 따르면 단일 반복에서 유효한 항목을 찾을 수 있습니다. 나중에 살펴보겠지만 이는 N=4 및 유효한 단일 항목인 $N_\text{optimal}=1$이기 때문입니다.
기하학적 설명
Grover의 알고리즘이 작동하는 이유를 확인하려면 기하학적 관점에서 알고리즘을 연구해보겠습니다. $\ket{\text{bad}}$를 검색 문제에 대한 솔루션이 아닌 모든 상태의 중첩이라고 가정합니다. $M$개의 유효한 솔루션이 있다고 가정합니다.
$$\ket{\text{bad}}=\frac{{1}{\sqrt{N-M}}\sum_{x:f(x)=0}\ket{x}$$
$\ket{\text{good}}$ 상태는 검색 문제에 대한 솔루션인 모든 상태의 중첩으로 정의됩니다.
$$\ket{\text{good}}=\frac{{1}{\sqrt{M}}\sum_{x:f(x)=1}\ket{x}$$
good 및 bad는 항목이 유효하지 않거나 유효하지 않기 때문에 상호 배타적인 집합이므로 상태 $\ket{\text{good}}$ 및 $\ket{\text{bad}}$는 직교합니다. 두 상태 모두 벡터 공간에서 평면의 직교를 형성합니다. 이 평면을 사용하여 알고리즘을 시각화할 수 있습니다.
이제 $\ket{\psi}$이 $\ket{\text{good}}$ 및 $\ket{\text{bad}}$에 걸쳐있는 평면에 있는 임의의 상태라고 가정합니다. 해당 평면에 있는 모든 상태는 다음과 같이 표현될 수 있습니다.
$$\ket{\psi}=\alpha\ket{\text{good}} + \beta\ket{\text{bad}}$$
여기서 $\alpha$ 및 $\beta$은 실수입니다. 이제 리플렉션 연산자 $R_{\ket{\psi}}$을 소개하겠습니다. 여기서 $\ket{\psi}$는 평면에 있는 큐비트 상태입니다. 연산자는 다음과 같이 정의됩니다.
$$R_{\ket{\psi}}=2\ket{\psi}\bra{\psi}-\mathcal{I}$$
의 방향에 대한 리플렉션으로 기하학적으로 해석될 수 있기 때문에 $\ket{\psi}$$\ket{\psi}$에 대한 리플렉션 연산자라고 합니다. 이를 보려면 $\ket{\psi}$과 그 직교 보수 $\ket{\psi^{\perp}}$ 형식의 평면의 직교 기반을 사용합니다. 평면의 모든 상태 $\ket{\xi}$는 다음과 같은 기준으로 분해될 수 있습니다.
$$\ket{\xi}=\mu \ket{\psi} +
u {\ket{\psi^{\perp}}}$$
$R_{\ket{\psi}}$ 연산자를 $\ket{\xi}$에 적용하는 경우:
$$R_{\ket{\psi}}\ket{\xi}=\mu \ket{\psi} –
u {\ket{\psi^{\perp}}}$$
연산자 $R_\ket{\psi}$은 $\ket{\psi}$에 직교하는 구성 요소를 반전하지만 $\ket{\psi}$ 구성 요소는 변경하지 않고 그대로 둡니다. 따라서 $R_\ket{\psi}$은 $\ket{\psi}$에 대한 리플렉션입니다.
Grover의 알고리즘은 모든 큐비트에 $H$를 처음 적용한 후 모든 상태의 균일한 중첩을 시작합니다. 이는 다음과 같이 작성될 수 있습니다.
$$\ket{\text{all}}=\sqrt{\frac{M}{N}}\ket{\text{good}} + \sqrt{\frac{N-M}{N}}\ket{\text{bad}}$$
따라서 상태는 평면에 있습니다. 동일한 중첩에서 측정할 때 올바른 결과를 얻을 확률은 $|\braket{\text{good}|{\text{all}}}|^2=M/N$일 뿐이며, 이것이 무작위 추측에서 기대하는 것입니다.
Oracle $O_f$는 검색 문제에 대한 솔루션에 부정적 단계를 추가합니다. 따라서 $\ket{\text{bad}}$ 축에 대한 리플렉션으로 작성할 수 있습니다.
$$O_f = R_{\ket{\text{bad}}}= 2\ket{\text{bad}}\bra{\text{bad}} – \mathcal{I}$$
마찬가지로 조건부 위상 편이 $O_0$은 상태 $\ket{0}$에 대한 반전된 리플렉션일 뿐입니다.
$$O_0 = R_{\ket{0}}= -2\ket{{0}\bra{0} + \mathcal{I}$$
이 사실을 알고 있으면 Grover 확산 연산 $-H^{\otimes n} O_0 H^{\otimes n}$이 $\ket{all}$ 상태에 대한 리플렉션이라는 것도 쉽게 확인할 수 있습니다. 다음을 수행하기만 하면 됩니다.
$$-H^{\otimes n} O_0 H^{\otimes n}=2H^{\otimes n}\ket{0}\bra{{0}H^{\otimes n} -H^{\otimes n}\mathcal{I}H^{\otimes n}= 2\ket{\text{all}}\bra{\text{all}} – \mathcal{I}= R_{\ket{\text{all}}}$$
Grover 알고리즘의 각 반복이 두 가지 리플렉션 $R_\ket{\text{bad}}$ 및 $R_\ket{\text{all}}$의 구상임을 증명했습니다.
각 Grover 반복의 결합된 효과는 각도 $2\theta$를 시계 반대 방향으로 회전하는 것입니다. 다행히 각도 $\theta$는 찾기가 쉽습니다. $\theta$는 $\ket{\text{all}}$과 $\ket{\text{bad}}$ 사이의 각도일 뿐이므로 스칼라 제품을 사용하여 각도를 찾을 수 있습니다. $\cos{\theta}=\braket{\text{all}|\text{bad}}$이므로 $\braket{\text{all}|\text{bad}}$를 계산해야 합니다. bad 및 good 측면에서 $\ket{\text{$\ket{\text{}}$$\ket{\text{all}}$}}$의 분해에서 다음을 따릅니다.
$$\theta = \arccos{\left(\braket{\text{all}|\text{bad}}\right)}= \arccos{\left(\sqrt{\frac{N-M}{N}}\right)}$$
레지스터 상태와 $\ket{\text{good}}$ 상태 간의 각도가 반복에 따라 감소하여 유효한 결과를 측정하는 확률이 높아집니다. 이 확률을 계산하려면 $|\braket{\text{good}|\text{register}}|^2$를 계산해야만 합니다. $\ket{\text{good}}$과 $\ket{\text{register}}$$\gamma (k)$ 사이의 각도를 나타냅니다. 여기서 $k$는 반복 횟수입니다.
$$\gamma (k) =\frac{\pi}{2}-\theta -k2\theta =\frac{\pi}{{2} -(2k + 1) \theta $$
따라서 성공 확률은 다음과 같습니다.
$$P(\text{success}) = \cos^2(\gamma(k)) = \sin^2\left[(2k +1)\arccos \left( \sqrt{\frac{N-M}{N}}\right)\right]$$
최적 반복 횟수
성공 확률은 반복 횟수의 함수로 작성할 수 있으므로 성공 확률 함수를 대략 최대화하는 가장 작은 양의 정수를 계산하여 최적 반복 횟수 $N_{\text{optimal}}$을 찾을 수 있습니다.
$\sin^2{x}$가 $x=\frac{\pi}{2}$에 대해 첫 번째 최댓값에 도달합니다.
$$\frac{\pi}{{2}=(2k_{\text{optimal}} +1)\arccos \left( \sqrt{\frac{N-M}{N}}\right)$$
다음 출력이 표시됩니다.
$$k_{\text{optimal}}=\frac{\pi}{4\arccos\left(\sqrt{1-M/N}\right)}-1/2 =\frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{1}{2}-O\left(\sqrt\frac{M}{N}\right)$$
마지막 단계에서 $\arccos \sqrt{1-x}=\sqrt{x} + O(x^{3/2})$.
따라서 $N_\text{optimal}$ to be $N_\text{optimal}=\left\lfloor \frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{{1}{2}\right\rfloor$로 선택할 수 있습니다.
복잡성 분석
이전 분석에서 유효한 항목을 찾기 위해 oracle $O_f$의 $O\left(\sqrt{\frac{N}{M}}\right)$ 쿼리가 필요합니다. 그러나 알고리즘을 시간 복잡성 측면에서 효율적으로 구현할 수 있나요? $O_0$은 $n$개의 비트에 대한 부울 연산 계산을 기반으로 하며 $O(n)$ 게이트를 사용하여 구현할 수 있는 것으로 알려져 있습니다. 또한 $n$개의 Hadamard 게이트의 두 계층도 있습니다. 따라서 두 구성 요소 모두는 반복당 $O(n)$개의 게이트만 필요합니다. $N=2^n$이므로 $O(n)=O(log(N))$를 따릅니다. 따라서 $O\left(\sqrt{\frac{N}{M}}\right)$ 반복과 반복당 $O(log(N))$개의 게이트가 필요한 경우, oracle 구현을 고려하지 않은 총 시간 복잡도는 $O\left(\sqrt{\frac{N}{M}}log(N)\right)$입니다.
알고리즘의 전반적인 복잡성은 궁극적으로 oracle $O_f$ 구현의 복잡성에 따라 달라집니다. 양자 컴퓨터에서 함수를 계산하는 것이 고전 컴퓨터보다 훨씬 복잡한 경우에는 기술적으로 더 적은 쿼리를 사용하더라도 양자 사례가 전체 알고리즘 실행 시간이 더 깁니다.
참조
Grover 알고리즘에 대해 계속 학습하려는 경우 다음 원본에서 확인할 수 있습니다.
[양자컴퓨터 기초 이론] 5. 그로버 알고리즘과 도이치 알고리즘
$\def\ket#1{\mid #1 \rangle}$
1. 양자 알고리즘의 기본
고전 컴퓨터에 비해 양자 컴퓨터가 빠른 이유는 하드웨어가 아니라 소프트웨어인 양자 알고리즘에서 기인한다. 그런데 거의 대부분의 양자 알고리즘은 확률증폭을 이용해서 문제를 풀어낸다. 이번 포스팅에서는 이 확률증폭에 대해서 알아보고 몇가지 기본적인 양자알고리즘에 대해서 적어보려고 한다.
a. 오라클(Oracle)
오라클(Oracle)은 함수의 일종으로 고대 그리스의 신탁에서 따온 명칭이다.
오라클은 입력값으로는 숫자나 문자 등 어떤 것이든 정해줄 수 있지만 출력값은 오직 1과 0만 반환해주는 함수이다. 이때, 1과 0은 Boolean Function의 일종으로 보아 True나 False를 반환한다고도 해석할 수 있다.
오라클을 다룰때는 함수가 입력값을 어떠한 처리를 해준 후에 1과 0을 반환하는 지에 대해서는 관심이 없다. 결과는 알지만 과정은 알지 못하는 것이다. 따라서 오라클을 블랙박스(Black Box)라고도 부른다.
또한, 컴퓨터에서는 모든 것을 1과 0의 bit로 처리할 수 있으므로 결국에는 다음과 같은 형태를 가질 것이다.
Oracle $f : {0,1}^n \rightarrow {0,1}$
양자 컴퓨터에서는 모든 연산은 Unitary Matrix하에서 이뤄진다. 따라서 이러한 오라클 함수도 Unitary Matrix의 형태로 표현된다. 구체적으로 다음을 만족하도록 짜여진다.
$U_f(\ket x) = \begin{cases} -\ket x \quad \mbox{ if } f(\ket x) = 1 \\ \ket x \qquad \mbox{ if } f(\ket x) = 0 \end{cases}$
이는 결과물의 확률 진폭만 Flip 시켜준다고 말할 수 있다.
예를 들어 다음과 같다.
3 큐빗짜리 큐빗을 생각해보자.
$\ket \psi = a_1\ket{000} + a_2 \ket{001} + a_3 \ket{010} + a_4 \ket{100} + a_5 \ket{011} + a_6 \ket{101} + a_7 \ket{110} + a_8 \ket{111}$
여기서 만약 오라클이 $\ket{010}$만 1로 반환하고 나머지는 0으로 반환할시 이에 대한 Unitary Matrix는 다음을 만족시켜주면 된다.
$\ket \psi = a_1\ket{000} + a_2 \ket{001} – a_3 \ket{010} + a_4 \ket{100} + a_5 \ket{011} + a_6 \ket{101} + a_7 \ket{110} + a_8 \ket{111}$
우리의 목표는 오라클이 True라고 말하고 있는 큐빗 상태($\ket 3 = \ket {010}$)를 모른다고 가정하고 찾아내는 것이다. 이때 목표로 해야하는 것이 바로 확률증폭이다.
b.확률증폭
$\psi$가 다중 Hadamard Gate(Kronecker Gate)를 통해 모든 상태가 나올 확률이 동일한 큐빗이라고 생각해보자.
즉 $\ket \psi = \sum_{j=1}^{8} \frac{1}{\sqrt 8} \ket j$이다.
이를 $U_f$에 통과시키면 다음과 같다.
$U_f \ket \psi = \frac{1}{\sqrt 8}\ket{000} +\frac{1}{\sqrt 8} \ket{001} – \frac{1}{\sqrt 8} \ket{010} + \frac{1}{\sqrt 8}\ket{100} +\frac{1}{\sqrt 8} \ket{011} + \frac{1}{\sqrt 8} \ket{101} + \frac{1}{\sqrt 8} \ket{110} + \frac{1}{\sqrt 8} \ket{111}$
이때 각 상태가 나올 확률은 같다. 하지만 베이시스(측정 방향)를 바꿔줌으로써 $\ket{010}$이 나올 확률만 증폭시켜줄 수 있다. 이를 진폭 증폭이라고 부르며 영어로는 amplitude amplification이다. (진폭 증폭은 직관적이지 않으므로 임의로 확률 증폭으로 부르자.)
이에 대한 여러가지 테크닉이 있지만 이 경우에는 “inversion about the mean” 테크닉을 사용해 줄 수 있다.
Inversion about mean은 말그대로 평균을 중심으로 대칭이동 시켜주는 것이다. 8개의 확률진폭을 각각 평균 대칭이동 시켜줄 경우 혼자 확률진폭이 음수로 변한 $\ket {010}$만 매우 높아지게 되며 다른 것이 나올 확률은 극도로 낮아지게 된다. 아래의 그림을 살펴보자.
이 확률증폭을 시켜주는 Operator $U_\psi$는 다음과 같다.
$U_\psi = 2\ket \psi \langle \psi \mid – I_{2^n} \quad (\ket \psi \mbox{ is hadamard state}) \\ \quad = H^{\otimes n} (\mid 0 \rangle^{\otimes n} \langle 0 \mid ^{\otimes n} – I^{\otimes n})H^{\otimes n}$
이를 Grover diffusion operator라고 말한다.
결론적으로 다음과 같다.
이는 확률이 증폭되는 가장 간단한 예시라고 말할 수 있다.
이를 적절하게 짜면 좀 더 실용적인 예시들에 적용할 수 있다.
2. Grover’s Searching Algorithm
고전 컴퓨터의 검색 알고리즘
이러한 확률증폭은 컴퓨터의 다양한 분야에서 사용할 수 있다. 그 중 한 분야는 검색이다. 우선 고전 컴퓨터에서 저장된 데이터를 찾을때 어떤 알고리즘으로 진행되는 지에 대해서 알아보자.
100개의 상자에 초콜릿이 들어있다고 생각해보자. 그 중 한 군데에는 민트 초콜릿이 들어있고 나는 이 민트 초코를 찾아서 먹고 싶다. 상자를 하나씩 열어보는 상황을 가정할때, 시간이 가장 적게 걸리는 케이스는 처음 연 상자에 민트 초코가 들어 있을 때이고, 시간이 가장 많이 걸리는 케이스는 99개를 열어도 들어있지 않아 마지막 상자에 초코가 들어있는 경우이다.
따라서 최소 1번, 최대 100번의 시간이 걸린다. 이를 일반화하면 상자의 집합을 S, 이 집합의 크기를 n이라고 두며 검색의 시간 복잡도 함수는 $O(n)$이라고 말할 수 있다. 각각의 상자를 연 후 이 데이터가 필요로 하는 데이터인지 아닌지에 대한 검정이 필요하며 이것을 수행하는 것이 곧 오라클이라고 말할 수 있다. 즉, 오라클 f를 최소 n번 수행하는 것이라고 말할 수 있다.
만약 이 상자의 집합에 대한 추가적인 정보가 있다면 좀 더 빠른 시간내에 찾을 수 있다. 예컨데 상자들이 초콜릿의 이름 순으로 정렬되어 있다고 가정하자. 100개의 상자 중 중간인 50번째 상자를 열어 봤을때 들어있는 초콜릿이 감귤 초콜릿 이면 감귤<민트 이므로 민트 초콜릿은 51~100번째에 들어있다고 생각할 수 있다. 그 다음 51~100번째의 75번째 상자를 열어봤을때 오렌지 초콜릿이 있었다면 민트<오렌지 이므로 민트 초콜릿은 51~75번째에 있다고 생각할 수 있다. 이런 방식으로 상자를 두개씩 분류해서 찾아나가는 기법을 Binary Search라고 말한다. 이 경우 $m-1< \log_2 n < m$ 인 m만큼의 상자를 열어보면 되므로 시간 복잡도 함수는 $O(\log n)$이다. 이 경우 정렬이 되지않은 데이터 셋에 비해 Exponentialy Improvement가 있다고 말하며 따라서 효율이 매우 높다고 말할 수 있다. 그러나 정렬이 되어있어야 한다는 전제조건이 있으므로 Binary Search가 사용이 불가능한 경우가 존재하기 마련이다. 그런데 Grover가 개발한 양자컴퓨터의 검색 알고리즘은 정렬이 되지 않은 열에 대해서 $O(\sqrt n)$만큼의 효율을 보인다. 이는 Quadratic Improvement라고 말하며 Exponentially Improvement만큼은 아닐 지라도 효율이 매우 높다고 말할 수 있다. 이에 대해서 구체적으로 알아보자. Grover’s Algorithm Grover’s Algorithm의 대략적인 과정은 다음과 같다. 집합 S의 크기 N을 파악하여 $2^{n-1} \leq N\leq2^n$인 n을 찾자. 찾고자 하는 Basis Ket의 확률 진폭을 뒤집는 오라클 행렬 $U_f$를 설계하거나 가져오자. 이는 사전에 주어질 수도 있고 데이터베이스에서 추출할 수도 있다. $U_fU_\psi$를 $\sqrt {2^n}$번 시행한 후 측정하자. 측정된 상태가 찾고자 하는 데이터의 위치를 의미한다. 일반적인 Searching Algorithm은 상자에서 꺼낸 후 데이터가 원하는 데이터인지 아닌지에 대한 검정, 즉 각각의 상자마다 오라클을 시행해야 했다면 Grover’s Algorithm은 상자 전체 (케이스 전체)에 대해 한꺼번에 오라클을 시행해본 후($ U_f$) 결과물을 확인하는 것이라고 말할 수 있다. 사실 1번에서 소개한 확률증폭에 대한 알고리즘을 여러번 시행한 것이다. 여러번 시행한 이유는 1번의 케이스에서는 큐빗이 3개이고 상태가 8개이므로 한번의 시행으로도 확률이 비교적 빠르게 수렴했지만 127:1,255:1 같은 케이스에서는 한번으로는 부족하기 때문이다. 결과물로 나온 큐빗이 데이터의 위치를 의미한다. 물론 확률이 0이 아닌 이상 오류는 존재하며 오류의 확률은 $O(\frac{1}{N})$이다. 3. Deutsch - Jozsa Algorithm Deutsch(도이치) 알고리즘은 퀀텀 컴퓨터의 초창기에 제안된 알고리즘이다. 비록 실용성은 떨어지지만 양자컴퓨터를 이용해 고전 컴퓨터보다 천문학적으로 앞서는 효율을 낼 수 있음을 보여준 첫번째 사례이기도 하다. Deutsch - Jozsa Algorithm(도이치 - 조자 알고리즘)은 이 Deutsch Algorithm을 다중 큐빗으로 확장시킨 사례이다. 이 알고리즘이 푸는 문제는 다음과 같다. 함수 $f:{0,1}^n \rightarrow {0,1}$는 Balanced 함수인가? Constant 함수인가? Balanced 함수라고 함은 정의역 원소의 절반은 0으로, 나머지는 1로 맵핑되는 함수를 의미하고, Constant 함수라 함은 모든 정의역이 1 혹은 0 으로 매핑되는 함수를 의미한다. 이 또한 오라클의 일종으로 볼 수 있다. 고전 컴퓨터에서 인풋의 총개수 $2^n$개에 대해서 확인할때 최고의 경우에는 첫번째 시행에 0이 나오고 두번째 시행에서 1이 나와 constant가 아님을 바로 알게되는 경우이다. 반대로 최악의 경우에는 $2^{n-1}$까지 시행에서 모두 0 혹은 1이 나와 $2^{n-1}+1$번째 시행에서야 balance인지 constant인지 확인할 수 있는 경우이다. 물론 함수가 constant일때는 무조건 $2^{n-1}+1$번째 까지 검사를 해봐야한다. Deutsch - Jozsa Algorithm의 경우, 시간복잡도 함수는 무려 O(1)이다. Hadamard Math 이러한 압도적인 효율은 Hadamard Gate의 수학적 특징에서 기인한다. $H \ket 0 = \frac{\sqrt 2}{2}(\ket 0 + \ket 1)$ $H \ket 1 = \frac{\sqrt 2}{2}(\ket 0 - \ket 1)$ 즉, $u \in {0,1}$에 대해 다음과 같이 쓸 수 있다. $H \ket u = \frac{\sqrt 2}{2} (\ket 0 +(-1)^u \ket 1) = \frac{\sqrt 2}{2} \underset{v \in {0,1}}{\sum} (-1)^{uv} \ket v$ (-1)을 곱해주는 것은 제곱 항인 확률에는 영향을 미치지 않지만 페이즈에는 영향을 미친다. 물리학자들은 이를 일컬어 phase change라고 부른다. 큐빗이 여러개로 확장될 경우는 다음과 같이 일반화 할 수 있다. $H^{\otimes n} \ket u = H\ket u_1 \otimes H \ket u_2 \otimes … \otimes H \ket u_n= \frac{1}{\sqrt{2^n}} \underset{v \in {0,1}^n}{\sum} (-1)^{u\cdot v} \ket v$ Deutsch - Jozsa Algorithm에서는 $\ket u = \ket{00…001}$인 n+1 짜리 큐빗을 사용한다. 이 경우 $u \cdot v = v_{n+1}$이 되므로 다음과 같이 적을 수 있다. $H^{\otimes n +1} \ket {00…01} = \frac{1}{\sqrt{2^{n+1}}} \underset{v \in {0,1}^{n+1}}{\sum} (-1)^{v_{n+1}} \ket v $ $= H^{\otimes n} \ket 0 ^{\otimes n} \otimes H \ket 1$ Deutsch - Jozsa Algorithm $U_f$ 이전 까지는 위에서 설명한 상황을 표현해주는 회로이다. $U_f$는 다음과 같은 함수이다. $U_f (\ket x ^{\otimes n} \otimes \ket y) = \ket x ^{\otimes n} \otimes \ket {y \oplus f(x)}$ $\ket x^{\otimes n}$과 $\ket y$는 각각 다음과 같다. $\ket x^{\otimes n} = H^{\otimes n} \ket 0 ^{\otimes n} = \frac{1}{\sqrt {2^n}}\underset{x \in {0,1}^n}{\sum} (-1)^{f(x)} \ket x$ $\ket{y} = H \ket 1 = \frac{1}{\sqrt 2} (\ket 0 - \ket 1)$ 이를 $U_f$에 넣으면 다음과 같다. $U_f (\ket x ^{\otimes n} \otimes \ket y) = ( \frac{1}{\sqrt {2^n}}\underset{x \in {0,1}^n}{\sum}\ket x) \otimes (\frac{\sqrt 2}{2} \ket{f(x)} - \frac{\sqrt 2}{2}\ket{1\oplus f(x)})$ 만약 f(x)가 0이면 $(\frac{\sqrt 2}{2} \ket 0 - \frac{\sqrt 2}{2}\ket{1})$ 만약 f(x)가 1이면 $(\frac{\sqrt 2}{2} \ket 1- \frac{\sqrt 2}{2}\ket 0)$ 이는 다시 다음과 같이 합쳐서 쓸 수 있다. $(-1)^{f(x)}\frac{\sqrt 2}{2} (\ket 0 -\ket 1)$ 이 확률은 얽힘에 의해서 앞부분으로 전이된다. 따라서 다음과 같이 쓸 수 있다. $U_f (\ket x ^{\otimes n} \otimes \ket y) = ( \frac{1}{\sqrt {2^n}}\underset{x \in {0,1}^n}{\sum} (-1)^{f(x)} \ket x)(\frac{\sqrt 2}{2} \ket 0 -\frac{\sqrt 2}{2} \ket 1)$ 뒷 부분은 일종의 상수이다. 앞 부분에는 오라클 f(x)가 $(-1)^{f(x)}$의 형태로 들어가게 되었다. 이를 phase kickback이라고 한다. 여기에 Hadamard Gate를 다시 적용해보자. 위에서 기술한 Hadamard Gate에 대한 공식을 이용하자. $H^{\otimes n}(\frac{1}{\sqrt {2^n}}\underset{x \in {0,1}^n}{\sum} (-1)^{f(x)} \ket x) = \frac{1}{2^n}\underset{x \in {0,1}^n}{\sum} (-1)^{f(x)} \underset{v \in {0,1}^n}{\sum} (-1)^{x\cdot v}\ket v$ 만약 f(x)가 Constant라면 f(x)=c 이므로 밖으로 빼낼 수 있다. $=\frac{1}{2^n}(-1)^{f(0)} \underset{v \in {0,1}^n}{\sum} [ \underset{x \in {0,1}^n}{\sum} (-1)^{x\cdot v}]\ket v$ 이때 $\ket v = \ket {0}^{\otimes n}$일시 $\forall x, x \cdot v = 0 $이므로 $[ \underset{x \in {0,1}^n}{\sum} (-1)^{x\cdot v}] = 2^n$이며 $\ket v eq \ket 0^{\otimes n}$일시 x의 조합에 대해 $x \cdot v$의 절반은 0이고 절반은 1이므로 $[ \underset{x \in {0,1}^n}{\sum} (-1)^{x\cdot v}] = 0$이다. 따라서 v와 x의 조합에 대해 다음의 결과물이 된다. $H^{\otimes n}(\frac{1}{\sqrt {2^n}}\underset{x \in {0,1}^n}{\sum} (-1)^{f(x)} \ket x) = (-1)^{f(0)}\ket{0}^{\otimes n}$ 이를 측정하면 100%확률로 $\ket 0 ^{\otimes n}$이 된다. 만약 f(x)가 Balanced라면 다음과 같다. $=\frac{1}{2^n}\underset{v \in {0,1}^n}{\sum} [ \underset{x \in {0,1}^n}{\sum}(-1)^{f(x)} (-1)^{x\cdot v}]\ket v$ 이때 $\ket v = \ket 0^{\otimes n}$의 케이스에서는 $(-1)^{x \cdot v} =(-1)^0=1$이 되므로 다음과 같이 쓸 수 있다. $=\frac{1}{2^n}\underset{v \in {0,1}^n}{\sum} [ \underset{x \in {0,1}^n}{\sum}(-1)^{f(x)} ]\ket v$ 그리고 이중 절반은 0이므로 $(-1)^{f(x)} =(-1)^0 =1$이고, 1이므로 $(-1)^{f(x)} =(-1)^1 =-1$이다. 따라서 $[ \underset{x \in {0,1}^n}{\sum} (-1)^{f(x)}] = 0$이므로 $\ket 0 ^{\otimes n}$이 측정될 확률은 0이다. 정리하면 f(x)가 Constant일시 $\ket 0 ^{\otimes n}$가 측정될 확률이 100%이며 f(x)가 Balanced일시 $\ket 0 ^{\otimes n}$가 측정될 확률은 0%이다. 따라서 Deutsch - Jozsa Algorithm을 통해 측정된 큐빗을 관찰함으로써, f(x)가 Balanced인지 Constant인지 알 수 있다. 지금까지 Grover’s Algorithm과 Deutsch’ Algorithm을 살펴보았다. 이 두 알고리즘은 양자 알고리즘의 기본이라고 볼 수 있으며 확률전이와 확률증폭이 어떤 식으로 이뤄지는 지 공부할 수 있는 좋은 사례이다. 어떻게 이뤄지는 지 확실히 숙지해두자. Sutor, R. (2019). Dancing With Qubits. Birmingham,UK:Packt Bernhardt, C. (2019). Quantum computing for everyone. Boston, Massachusetts:The MIT Press
양자 컴퓨터 시대의 문턱에서
피터 쇼어Peter Shor의 소인수 분해 알고리즘은 사람들이 양자 컴퓨터에 많은 관심을 갖게 된 시발점이었다. 양자 컴퓨터를 이용해 현실적으로 중요한 문제를 해결하는 데 필요한 연산량을 혁신적으로 줄일 수 있다는 사실은 많은 과학자들 사이에서 상당한 반향을 일으켰다. 만약 양자 컴퓨터가 소인수 분해를 더 빠르게 할 수 있다면, 다른 문제들도 빠르게 풀 수 있지 않을까? 양자 컴퓨터가 빠르게 풀 수 있는 문제에는 어떤 것들이 있을까? 이러한 종류의 질문들은 지난 20여 년간 양자 컴퓨터라는 분야를 이끌어 온 중요한 연구 화두였다. 이번 글에서는 양자 컴퓨터를 이용해서 할 수 있는 여러 유용한 일들에 대해 살펴보고자 한다.
신물질 개발
1 HORIZON “고체물리학의 관점에서 본 구석기, 신석기, 청동기, 철기 시대”를 참고할 수 있다. 인류의 역사를 돌이켜 보면, 새로운 시대의 도래에는 거의 빠짐없이 신물질의 발견이 수반되었다. 먼 과거로 시간을 되돌려보면 인류의 역사는 사람들이 사용하는 도구의 종류로 구분되곤 했었다. 석기 시대의 인류는 자연에 존재하는 돌을 이용해 도구를 만들었지만, 시간이 지나면서 인간은 차츰 제련을 통해 더 강하고 유용한 도구를 만들어냈다. 이것이 청동기 시대의 도래이고, 이후 철기 시대는 우리에게 알려진 수많은 문명들의 시발점이 되었다.1 비교적 최근의 역사를 짚어봐도 마찬가지다. 우리 주변에서 항상 볼 수 있는 플라스틱, 전지, 유리 등의 물질이 없는 삶은 상상하기 힘들다. 이처럼 신물질의 발견은 인류의 삶이 직접적으로 크게 바뀌는 중요한 계기가 되곤 한다. 20세기에 들어선 뒤 물리학자들은 자연에 존재할 수 있는 모든 물질의 특성을 설명할 수 있는 이론을 만들어낸다. 바로 양자 역학이다. 우리에게 무한한 연산 능력만 있다면, 양자역학을 기술하는 공식을 이용해서 자연에 존재할 수 있는 모든 물질의 특성을 정확하게 계산해서 예측할 수 있다. 하지만 근사 없이 이러한 계산을 하기 위해 필요한 전체 연산량은 현재 지구상에 존재하는 컴퓨터를 전부 동원해도 턱없이 부족할 만큼 크다. 기존의 컴퓨터로 양자역학적인 효과를 다루기 위해서는 엄청나게 많은 연산이 필요하기 때문이다. 미국 에너지부에서 몇 년에 걸쳐 책정한 슈퍼컴퓨팅 관련 예산만 해도 2조 원이 넘는데[1], 이러한 엄청난 예산에도 불구하고 양자역학적인 효과가 강하게 나타나는 물질의 특성을 이론적으로 예측하기에는 아직도 많은 어려움이 많다.
연재글 양자 컴퓨터 시대의 문턱에서 양자 컴퓨터의 기원 양자 알고리즘: 소인수 분해 알고리즘 양자 알고리즘의 세계 양자 오류보정 양자 우월성 NISQ 시대의 양자 컴퓨터 그렇기 때문에, 많은 경우 물질의 특성을 파악하기 위해서는 직접 물질을 만들어 보는 수고를 할 수밖에 없다. 예를 들어 새로운 태양 전지를 만드는 것이 목표라고 가정해 보자. 두 가지의 물질을 혼합해서 태양 전지를 만들고자 한다면, 분명 최대의 효율을 낼 수 있는 혼합 비율이 존재할 것이다. 그렇다면 최대 효율의 혼합 비율은 어떻게 찾을 수 있을까? 각각의 혼합 비율에 대한 전지의 효율을 하룻밤 만에 직접 계산할 수 있다면, 최대의 효율이 얼마인지와 이를 위한 혼합 비율을 모두 알 수 있을 것이다. 이는 실로 중요한 정보다. 최대 효율의 계산을 통해 기존의 전지에 비해 새로운 전지가 얼마나 뛰어난지 알 수 있고, 최적화된 혼합 비율의 구체적인 정보를 통해 새로운 전지를 직접 만들어내는 공정 과정으로 바로 넘어갈 수 있기 때문이다. 그에 반해 이러한 연산을 할 수 없다면, 직접 각각의 혼합 비율 샘플을 여러 개 만들어서 매번 효율을 시험해보는 수밖에 없다. 이를 위해 필요한 인적, 물적 자원이 적지 않다는 것은 독자들도 쉽게 이해할 수 있으리라 생각한다. 일단 이러한 실험을 하기 위해서는 물질을 혼합하는 실험실 자체가 만들어져야 하고, 또 효율을 테스트하는 데 시간이 필요하기 때문이다. 일련의 실험을 직접 수행할 사람들이 필요하다는 사실은 두말할 나위 없다.
양자 컴퓨터가 소인수 분해를 더 빠르게 할 수 있다면, 다른 문제들도 빠르게 풀 수 있지 않을까? 양자 컴퓨터가 빠르게 풀 수 있는 문제에는 어떤 것들이 있을까? 이러한 질문은 지난 20여 년간 양자 컴퓨터라는 분야를 이끌어 온 중요한 연구 화두였다. 물질들의 특성을 예측하기 위해 만들어진 계산 방식이 있긴 하지만, 문제는 물질 속에 존재하는 수많은 전자들 사이의 강한 전기적 상호 작용의 효과를 정확히 계산하기에는 많은 어려움이 있다는 점이다. 결과적으로 전자 간의 상호작용 때문에 일어나는 현상을 이해하는 데에도 어려움이 생기게 된다. 양자 컴퓨터는 전자 간의 상호 작용이 강한 물질이 작동하는 원리를 이해하는 데 큰 도움을 줄 것으로 예상된다. 이론으로 설명되는 초전도 물질과 비교했을 때, 고온 초전도 현상을 나타내는 물질은 훨씬 높은 온도에서도 전기를 에너지 손실 없이 보낼 수 있다. 하지만 안타깝게도 고온 초전도체가 어떤 방식으로 작동하는지에 대한 미시적인 이해는 아직도 크게 부족하다. 만약 상온에서도 이런 초전도 현상을 나타내는 물질을 만들어 낼 수 있다면, 이는 인류의 에너지 소모를 크게 줄일 수 있는 중요한 일이 될 것이다. 양자 컴퓨터를 이용하면 고온 초전도체 물성의 미시적인 이해를 돕는 데 필요한 시간을 크게 줄일 수 있을 것으로 기대된다.[3] 또 다른 중요한 예로 질소 고정 과정을 들 수 있다. 질소 고정 과정은 공기 중에 있는 질소를 암모니아로 바꾸는 일을 말하는데, 현대 사회에서 비료를 만들 때 가장 중요한 화학 작용 중 하나이다. 이렇게 암모니아를 만드는 방식은, 1900년대 초반 하버Fritz Haber라는 화학자가 만든 공정 방식을 아직까지도 이용한다.2 이 공정 과정에는 400도에 달하는 고온과 200기압에 달하는 고압 환경이 필요하고 이러한 환경을 유지하기 위해서는 상당한 에너지 소모가 수반된다. 실제로 현재 전 인류가 쓰는 에너지의 1% 내지 2% 정도가 해당 공정에 쓰인다고 알려져 있다.[2] 하지만 자연에서는 평범한 환경에서도 박테리아가 아무런 문제 없이 질소를 암모니아로 바꿀 수 있다. 만약 박테리아가 어떠한 방식으로 암모니아를 생성하는지 이해하면 에너지 효율이 훨씬 높은 공정 과정을 만들 수 있을지도 모른다. 최근 연구자들은 양자 컴퓨터를 이용해서 이러한 화학 반응이 어떻게 일어날 수 있는지 효율적으로 예측할 수 있다는 사실을 발견했다.3[4] 비록 필자가 제시한 예는 두 개에 불과하지만, 이처럼 우리는 아직도 인류에게 큰 영향을 미칠 수 있는 물질이 어떠한 원리로 작동하는지 정확하게 알지 못하는 경우가 많다. 물질의 특성을 예측할 수 있는 공식은 이미 우리에게 알려져 있지만, 공식을 통해서 특성을 계산하는 데에는 많은 어려움이 있기 때문이다. 양자 컴퓨터를 이용하면 물질의 특성을 파악하기 위한 계산량을 크게 줄일 수 있을 것으로 예상된다.
2 하버는 이 공로로 노벨 화학상을 받았다.
3 HORIOZN “양자정보: 생물학에서 컴퓨터까지”를 참고할 수 있다.
이러한 계산을 수행하기 위해서는 최소한 수만 내지 수십만 개의 큐빗을 갖고 있는 양자 컴퓨터가 필요할 것이라는 것이 학계의 정설이다. 현재 나와 있는 양자 컴퓨터의 큐빗이 100개도 안 되는 것을 생각하면, 아직도 갈 길이 멀어 보이는 것이 사실이다. 하지만 필자는 이러한 실험과 이론 사이의 간극이 계속해서 좁혀져 왔다는 사실을 강조하고 싶다. 큐빗의 숫자는 계속해서 늘어나고 있고, 대규모의 양자 컴퓨터를 만들기 위해서 쏟아붓는 자원과 노력은 시간이 지날수록 계속해서 더 많아지고 있다. 뿐만 아니라, 물성 계산에 필요한 연산량도 연구자들의 노력으로 계속 줄어들고 있다. 이러한 발전이 계속되면 생각보다 머지않은 시일 내에 큰 규모의 양자 컴퓨터를 이용해서 유용한 계산을 할 수 있게 될지도 모른다. 물론 그 시기가 정확히 언제일지는 예측하기 힘들지만 말이다. 필자는 간혹 이런 생각을 한다. 이렇게 물질들의 특성을 손쉽게 계산할 수 있는 때가 오면, 인류의 발전 양상은 이전과는 전혀 다른 모습을 보일 수도 있지 않을까? 여태껏 인류가 신물질을 발견해온 방법은 실험을 바탕으로 한 예측이었다. 만약 실험을 하는데 필요한 자원과 시간을 줄일 수 있다면 새로운 물질을 발견하고 공정 과정을 만들어내는 시간을 크게 단축할 수 있을지도 모른다. 인류의 거대한 발전의 이면에 항상 신물질의 발견이 있었다는 사실을 기억해 보면, 어쩌면 양자 컴퓨터의 도래는 인류의 발전 속도가 비약적으로 증가하는 중요한 역사의 한순간이 될지도 모르겠다는 생각이 든다.
빠른 최적화 수많은 산업체나 금용, 정부기관에서 결정을 내릴 때 어느 것이 최적의 선택인지 알아내는 데 많은 시간과 자원이 들어간다. 특히 요즘처럼 수많은 데이터가 산재하고 처리해야 할 결정의 수가 많아진 시대에는 어떠한 결정을 내려야 하는지 선택하기 쉽지 않은 경우가 많다. 이렇게 많은 경우의 수 중에서 최대의 효율이나 이득을 내는 방법을 찾는 문제를 최적화 문제라고 부른다. 최적화 문제와 관련해, 양자 컴퓨터는 기존의 컴퓨터들보다 적은 연산량으로도 같은 최적화 값을 찾아낼 수 있다.
4 안타깝게도 양자역학적인 효과를 이용하기 위해서는 상자들을 양자역학적인 중첩상태로 만들 수 있어야 한다. 이러한 거시적인 물체를 중첩 상태로 만드는 일은 아직 물리적으로 매우 어렵다. 양자 컴퓨터가 최적화 문제 해결의 속도를 향상시킬 수 있는 비결의 이면에는 놀라운 사실이 하나 있다. 만약에 독자들이 필자에게 1000개의 닫힌 상자를 가져왔다고 생각해 보자. 이 중 하나의 상자에는 100만 원짜리 상품권이 들어있고 나머지 상자들은 전부 꽝이다. 상품권이 들어있는 상자를 찾기 위해서는 상자를 총 몇 번 열어봐야 할까? 최악의 경우에는 1000번을 열어봐야 할 테고, 평균적으로는 수백 번은 열어봐야 높은 확률로 상품권을 찾을 수 있을 것이다. 하지만 양자역학적인 효과를 이용하면 상자를 단 25번만 열어서 100%에 가까운 확률로 상품권을 찾는 것이 가능하다.4 이 놀라운 사실은 그로버Lov Grover의 알고리즘으로 알려져 있다.[6] 1990년대 벨 연구소에서 일하고 있던 그로버는 쇼어의 소인수 분해 알고리즘에 자극을 받아 양자 알고리즘에 대한 연구를 시작했다. 그는 다음과 같은 사실을 발견했다. 두 개의 값을 갖는 함수 \(f(x)\)를 생각해 보자. 이 함수가 단 하나의 \(x\)에 대해서는 \(f(x)=1\)의 값을 지니고 나머지 \(x\)에 대해서는 \(f(x)=0\)의 값을 지닌다고 가정해보자. 만약 가능한 \(x\)의 범위가 \(1\)부터 \(N\)이라면 \(f(x)\)를 대략 \(\frac{\pi}{4}\sqrt{N}\)번 계산해서 \(f(x)=1\)인 \(x\)를 찾을 수 있다. 여기에 \(N=1000\)의 값을 대입해 보면 대략 \(f(x)\)를 \(25\)번 정도 계산해서 답을 찾아낼 수 있다는 것을 알 수 있다. 위의 예에서 상자의 내용물을 확인하는 행위를, 함수를 계산하는 것으로 해석할 수 있다. 즉 상자를 열어 상품권이 나오는 경우를 \(1\)로, 꽝이 나오는 경우를 \(0\)으로 생각하면 된다. 그로버의 알고리즘은 이처럼 함수의 값을 계산하는 것 자체는 쉽지만, 특정한 조건을 만족하는 \(x\)의 값을 찾기는 어려운 경우에 유용하게 쓰일 수 있다. 그로버의 알고리즘을 이용하면 다양한 최적화 문제를 기존 컴퓨터에서 사용하는 알고리즘보다 빠르게 풀 수 있다. 최적화 값을 구하기 위해 기존 컴퓨터를 이용하는 알고리즘으로 \(N\)번의 계산이 필요하다면, 이 알고리즘을 그로버의 접근 방식을 이용한 양자 컴퓨터상에서는 대략 \(\sim \sqrt{N}\)번의 연산으로 계산할 수 있다는 식이다.
이 알고리즘의 작동 원리는 중고등학교 때 배우는 평면기하학을 통해 이해해 볼 수 있다. 알고리즘은 모든 상태가 같은 확률로 동시에 존재하는 중첩상태로부터 출발한다. 총 가능한 상태의 수가 \(N\)개이고 \(f(x)=1\)을 만족하는 \(x\)가 단 한 개 있다면, 이 중첩상태 \(|\psi\rangle\)는 다음과 같이 나타낼 수 있을 것이다.
\begin{equation}
|\psi\rangle = \frac{\sqrt{N-1} |\text{오답}\rangle + |\text{정답}\rangle}{\sqrt{N}}.
\quad \cdots \quad (1)
\end{equation}
이 상태는 정답, 즉 \(f(x)=1\)을 만족하는 \(x\)일 확률이 정확히 \(1/N\)이기 때문이다. 이 상태 \(|\psi\rangle\)를 그림으로 나타내보면 [그림1]과 같은 결과를 얻게 된다. 좀 더 풀어서 설명해 보자면 \(|\psi\rangle\)는 “오답”인 상태와 “정답”인 상태의 중첩상태이고, 우리는 이 상태를 2차원 평면에 존재하는 벡터로 이해할 수 있다. 그로버의 알고리즘은 [그림1]에 그려져 있는 벡터 \(|\psi\rangle\)를 두 가지의 간단한 연산을 이용해서 “정답”이라고 쓰여 있는 \(x\)축으로 옮기는 것이 목표이다. 이 상태에서 측정을 하게 되면 높은 확률로 정답을 얻을 수 있다. 첫 번째 연산은 양자 역학적으로 \(f(x)\)를 계산해서 \(f(x)=1\)인 양자 상태의 위상을 180도 바꾸는 일이고, 두 번째 연산은 상태가 \(|\psi\rangle\)에 있으면 위상을 180도 바꾸는 연산이다. 이 연산들은 이전 글 “양자 컴퓨터의 기원”에서 말했듯이, 양자 컴퓨터가 손쉽게 할 수 있는 계산들이다. 양자 컴퓨터에서 첫 번째 연산을 하기 위해서는 고전 컴퓨터에서 \(f(x)\)를 계산하는데 필요한 정도의 연산량으로 충분하고, 두 번째 연산을 위해서는 \(n\)개의 큐빗이 있을 경우 \(n\)에 비례하는 연산량으로 충분하다. 이 연산 과정들이 어떠한 일을 하는지는 그림으로 쉽게 이해할 수 있다. 첫 번째 연산은 “정답” 축에 대하여 대칭 이동을 하는 것이고 두 번째 연산은 \(|\psi\rangle\)에 대해서 대칭 이동을 하는 것이다. 때문에, 이러한 대칭 이동을 통해서 어떻게 \(|\psi\rangle\)을 “정답”축으로 이동시킬 수 있는지 이해하면 그로버의 알고리즘이 어떠한 원리로 작동하는지 쉽게 이해할 수 있다. 이제 이 두 연산을 어떻게 이용할 수 있는지 알아보자. 우선 “정답”축에 대한 대칭 이동을 하게 되면 우리는 [그림2]와 같은 결과를 얻게 된다. 그다음 \(|\psi\rangle\)에 대한 대칭 이동을 하게 되면 우리는 [그림3]과 같은 결과를 얻게 된다. 두 번의 연산을 통해서 “오답”축에 대한 각도인 \(\theta\)가 \(\theta + 2\theta = 3\theta\)로 바뀌게 된다. 이를 \(n\)번 반복하면 각도는 \((2n+1)\theta\)로 바뀐다. 정답상태에 가까워지기 위해서는 \((2n+1)\theta\)가 \(90\)도, 즉 \(\frac{\pi}{2}\)에 가까워져야 한다. 이를 위해서는 \(n\)이 다음과 같은 식을 만족해야 한다:
\begin{equation}
\begin{aligned}
n= \frac{\pi}{4}(\arcsin(N^{-\frac{1}{2}}))^{-1}-1.
\end{aligned}\quad \cdots \quad (2)
\end{equation}\(N\)이 충분히 커지게 되면 이 식은 \(n\approx \frac{\pi \sqrt{N}}{4}\)로 단순화된다. 이는 정확히 앞에서 필자가 말했던 식이다. 이를 통해 평균적으로 \(\sim N\)번 \(f(x)\)를 계산해 보아야 하는 고전적인 방법보다 훨씬 적은 시도로도 \(f(x)=1\)을 만족하는 \(x\)를 찾아낼 수 있다. 이것이 가능한 이유는 양자역학적인 간섭 및 보강효과 때문이다. 고전적인 방식으로는 직접 \(f(x)\)를 계산해서 그 결과를 확인해야 하지만, 양자 역학적인 방식을 이용하면 상쇄간섭을 통해 오답이 나올 확률을 줄일 수 있다.
5 비록 \(f(x)=1\)인 \(x\)가 하나밖에 없다고 가정했지만 그러한 \(x\)가 여러 개인 경우에도 비슷한 속도 향상을 가져올 수 있다. 그로버의 알고리즘이 중요한 이유는 범용성에 있다. 실제로 위에서도 보았듯 우리는 함수 \(f(x)\)에 대해서 그다지 특별한 가정을 하지 않았다.5 이는 쇼어의 소인수 분해에서 함수가 주기적인 특성을 보였다는 점과는 매우 다르다. 이 때문에 그로버의 접근 방식을 이용하면 훨씬 더 다양한 연산문제들에 대해서 속도 향상을 가져올 수 있다. 그로버의 접근 방식을 이용해서 기존 컴퓨터보다 문제를 빠르게 풀 수 있는 예로 최근에 나온 논문 하나를 소개해 보겠다.[7] 다음과 같은 상황을 생각해 보자. 독자 중 한 명이 새로 카페를 연다고 생각해 보자. 커피 메뉴로 두 가지 종류의 커피를 생각 중이다. 첫 번째 종류는 에스프레소 기계를 이용한 아메리카노, 라떼 같은 커피들이고, 두 번째 종류의 커피는 비교적 손쉽게 만들 수 있는 드립 커피다. 에스프레소 기계를 이용하면 더 비싼 값을 받고 다양한 손님을 모을 수 있지만, 대신에 더 많은 투자 비용이 필요하고 기계가 카페의 자리도 많이 차지한다. 드립 커피를 만들면 아메리카노나 라떼를 사려는 손님들을 받을 수는 없겠지만 대신에 투자 비용도 적고 자리도 적게 차지한다. 더 많은 투자를 해서 더 비싼 값을 받아야 할까, 아니면 더 적은 투자를 해서 박리다매를 해야 할까? 만약 카페 주인의 투자금이 천만 원이라고 가정해 보자. 그리고 에스프레소 기계 하나를 사는 데에는 75만 원, 드립 커피 기구에는 10만 원이 든다고 생각해 보자. 주인이 생각해 봤을 때, 에스프레소 기계 하나를 사면 대략 기계 하나로 시간당 15만 원을 벌어들일 수 있고, 드립 커피를 이용하면 시간당 만원을 벌어들일 수 있다. 또한 카페에는 대략 20평 정도만큼의 공간밖에 없다고 하자. 에스프레소 기계 하나를 설치하려면 3평 정도의 공간이 필요하지만 드립 커피를 만드는 데는 1평 정도의 공간이면 충분하다. 그렇다면 주인은 에스프레소 기계와 드립 커피 기구를 각각 몇 개씩 사야 할까? 이는 다음과 같은 문제로 나타낼 수 있다. \(x\)와 \(y\)를 에스프레소 기계와 드립 커피 기계의 숫자라고 하자. 우리는 다음과 같은 조건을 만족하는 \(x\)와 \(y\)중에서 최대한의 이득을 얻을 수 있는 \(x\)와 \(y\)를 찾아야 한다.
\begin{equation}
\begin{aligned}
75x + 15y &\leq 1000 \\
3x+ y &\leq 20
\end{aligned}\quad \cdots \quad (3)
\end{equation}여기서 총 이득은 \(15x+y\)이다. 어떻게 하면 최대한의 수익을 낼 수 있을까? 이는 혼합 정수 선형 계획법Mixed Integer Programming이라고 불리는 문제의 한 종류이고, 변수의 숫자가 많아질수록 최적값을 찾아내는데 필요한 연산량이 변수의 숫자에 대해 지수함수적으로 증가한다. 비록 그로버의 알고리즘이 푸는 문제는 위에서 제시한 문제와는 완전히 달라 보이지만, 그 밑바탕에 있는 아이디어를 이용해서 비슷한 속도 향상을 가져올 수 있다. 기존의 컴퓨터에서 최대한의 이득을 얻는 조건을 구하는데 필요한 연산량이 \(N\)이라고 하면 양자 알고리즘을 이용하면 대략 \(\sim \sqrt{N}\) 정도의 연산량만 필요하다.[7]
그로버의 알고리즘이 중요한 이유는 범용성에 있다. 실제로 위에서도 보았듯 우리는 함수 \(f(x)\) 대해서 그다지 특별한 가정을 하지 않았다. 이는 쇼어의 소인수 분해에서 함수가 주기적인 특성을 보였다는 점과는 매우 다르다. 이처럼 일상생활에서 쉽게 생각할 수 있는 일반적인 최적화 문제에 대해서도 양자 컴퓨터는 기존 컴퓨터보다 훨씬 적은 연산량으로 같은 계산을 할 수 있다. 최적화 문제는 사회 전반에 걸쳐 다양한 곳에 쓰이기 때문에, 양자 컴퓨터가 기존 컴퓨터보다 최적화 문제를 빠르게 풀기 시작하는 날이 오면, 신물질 발견보다 더 큰 영향을 인류에 미칠지도 모른다. 아쉽게도 이러한 문제들로부터 얻을 수 있는 속도 향상은 양자 시뮬레이션으로부터 얻을 수 있는 속도 향상에 비해서는 작은 편이다. 양자 시뮬레이션 같은 경우에는 기존 컴퓨터에서 지수함수적으로 늘어나는 연산량을 대수적으로 늘어나는 연산량으로 줄일 수 있지만, 이러한 최적화 문제들은 그렇지가 않다. 필요 연산량이 고전 컴퓨터에서 지수함수적으로 늘어나면 양자 컴퓨터에서도 지수함수적으로 늘어나게 된다. 단지, 지수함수적으로 늘어나는 속도가 다를 뿐이다. 예를 들어서, 고전 컴퓨터에서 필요한 연산량이 \(2^n\)이라고 하면 양자 컴퓨터에서는 필요한 연산량이 \(2^{n/2}\)인 식이다. 이 때문에 양자 컴퓨터를 이용한 속도 향상을 가져오기 위해서는 상당히 큰 규모의 양자 컴퓨터가 필요할 것으로 예상된다. 이렇게 속도 향상이 제한적인 이유는 위에서 다루었던 그로버 알고리즘의 작동 원리를 통해서 유추해 볼 수 있다. 그로버의 알고리즘을 액면 그대로 사용하면 우리는 함수를 \(\sim \sqrt{N}\)번 계산하는 것을 피할 수가 없다. 이는 “오답”축과 떨어져 있는 각도 \(\theta\)가 단조적으로 증가하기 때문이다. 이 때문에 그로버의 알고리즘에서 사용하는 대칭이동을 \(\sim\sqrt{N}\)번보다 적게 사용하면 정답 확률은 \(\sim\sqrt{N}\)번 했을 때보다 작을 수밖에 없다. 특히 \(N=2^n\)이라고 가정했을 때 대칭 이동을 \(n\)에 대해서 대수적으로 증가하는 횟수만큼만 적용하면 정답 확률은 여전히 \(n\)에 대해서 지수함수적으로 작을 수밖에 없다. 실제로 그로버의 알고리즘처럼 모든 함수에 대해서 답을 찾아낼 수 있는 알고리즘은 함수를 최소한 \(\sim \sqrt{N}\)번 계산해야 한다는 사실이 알려져 있다.[8] 물론 주기함수처럼 좀 더 특별한 특성을 지니는 함수들의 경우에는 그 특성을 이용해서 더 빠르게 답을 찾아낼 수 있을지도 모른다. 하지만 그러한 함수들의 특성을 이용하기 위해서는 그로버의 알고리즘과는 다른 알고리즘을 사용해야 할 것이다. 어떠한 특성을 이용하면 그로버의 알고리즘보다 더 많은 속도 향상을 가져올 수 있는지에 관한 연구는, 현대 양자 알고리즘 연구에서 중요한 화두이다.
마치며 대규모의 양자 컴퓨터가 만들어지면 인류 사회는 지금과 비교했을 때 상당한 변화가 있을 것으로 예상한다. 양자 컴퓨터를 이용하면 정확한 계산을 통해서 물질들의 작동 원리와 특성을 손쉽게 파악할 수 있고, 다양한 산업체에서 쓰이는 최적화 문제들에 대해서도 많은 속도 향상을 가져올 수 있기 때문이다. 하지만 그런 미래에 도달하기 위해서는 아직도 많은 노력이 필요하다는 점을 강조하고 싶다. 이러한 문제들을 푸는데 쓰이는 알고리즘을 사용하기 위해 필요한 양자 컴퓨터의 크기는 현재 나와 있는 양자 컴퓨터의 크기에 비해 너무나도 크다. 이 때문에 알고리즘들을 수행하기 위해 필요한 양자 컴퓨터의 크기와 연산량을 줄이는 연구는 앞으로도 계속되어야 할 중요한 연구 방향이다. 더불어 이러한 알고리즘을 직접 수행할 수 있는 대규모 양자 컴퓨터의 개발이 중요한 것은 두말할 나위도 없다. 다음 글에는 그러한 컴퓨터를 만들기 위해서 반드시 수반되어야 하는 양자 오류 보정이라는 분야에 대해서 이야기해보도록 하겠다.
[ 양자 알고리즘 ] 쇼어(Shor) , 그로브(Grove) 알고리즘 개념 및 이해
그로버(Grover) 알고리즘은 쇼어(shor)알고리즘이 등장한 후 2년뒤, 1996년에 인도계 미국 컴퓨터공학자였던 롭 그로버(Lov Grover)에 의해 고안된 개념으로 정렬되지 않은 데이터베이스를 선형시간(On time)내 검색케 해주는 알고리즘이었다. 그로버 검색 알고리즘(Grover Search Algorithm)이라고도 하는데, 정렬되지 않은(unstructured) 데이터베이스(database)로부터 원하는 특정 데이터를 찾는 알고리즘이다. 현대에 이 알고리즘이 최적화 된다면 현재의 대칭키 안전성을 더이상 보장할 수 없다는 의견도 있다. NIST는 이와 관련된 결과를 2016년 4월 NISTIR 8105를 통해 Report on Post-Quantum Cryptography”에 발표하기도 했다.
그로버의 알고리즘은 정렬되지 않은 데이터베이스를 시간 안에 검색케 해준다. 예를 들어 이는 누군가의 전화번호만을 알고 있을 때 전화번호부에서 그의 이름을 찾는 데 쓰일 수 있다. 그로버의 알고리즘은 쇼어의 인수분해 알고리즘처럼 인상적인 속도향상을 가져오진 않았다. 지수적인 속도향상이 아니라 (말하자면, 원소의 수를 제곱근한 값에 비례하는) 이차(quadratic) 속도향상이었다. 그 완만한 속도향상은 그로버 알고리즘의 광범위한 응용가능성과 맞선 균형을 이룬다.
그로버가 그의 알고리즘을 데이터베이스 검색 측면으로 설명하긴 했지만, 실은 그보다 더 일반적이다. 검색 대상은 어떤 함수를 충족하는 뭔가이기만 하면 – 다시 말해 어떤 문제의 답이기만 하면 된다. (기술적으로 말하자면, 그 목표는 ‘어떤 함수의 역inverse of a function‘이다.) 그런 문제는, 예를 들어, ‘이 메시지를 복호화하는 데 쓸 수 있는 키는 뭐지?’같은 것이 될 수 있다. 다시 말해, 그로버의 검색 알고리즘은 암호를 깨는 무차별대입공격brute-force cracking의 속도향상에 쓰일 수 있다. 심지어 인수분해 기반이 아닌 암호에도 그렇다. 또 이는 숫자 세트의 일반값(average) (평균(mean)이나 중앙값(median) 추정에도 쓰일 수 있다.
그로버의 알고리즘은, 다른 여러 양자알고리즘처럼, 확률적(probabilistic)이다. 각 실행은 옳은 답을 낼 가능성과, 낮지만 틀린 답을 얻게 할 가능성을 갖는다. 이는 매우 이상해 보이지만, 실은 보기보다 훨씬 유용하다. 답이 함수의 해이기 때문에, 만일 알고리즘이 틀린 답을 낸다면 즉각적으로 알아차릴 수 있다. n개 원소 시스템에서 해를 구하려 시간을 써버렸는데 틀린 답만을 얻었다면, 꽤 우울할 것이다. 하지만, 길고 느린 계산이 여러번 반복돼야 한다면 그 해를 구하는 전체 시간은 여전히 이고 결정적인(deterministic) 고전 알고리즘을 이용하는 것보다 훨씬 더 빠를 것이다. (계산이 틀릴 확률은 n과 함께 늘어나지 않고, 이는 오류 가능성이 허용되는 이유다.)
그로버의 알고리즘을 일반화한 것은 ‘충돌 문제collision problems‘를 푸는 데 쓰일 수 있다. 어떤 함수를 만족하는 것 하나만을 구하는 게 아니라 같은 답을 구하기 위한 여러 원소를 찾을 수 있다는 얘기다. 공간상의 물리적 충돌, 그리고 생일이 같은 두 사람을 찾는 것과 같은 더 일반적인 문제를 이해할 때 유용하다. 그로버의 원래 알고리즘처럼, 이는 동일한 해시를 얻을 수 있는 두 숫자를 찾는 암호 공격의 기반을 구성할 수 있다(이것의 고전적 버전은 ‘생일 공격’이라는 유쾌한 이름이 있다).
2) 수학적 원리
Classical algorithm으로는 N개의 데이터 중에서 특정 데이터를 찾으려면 최악의 경우 대략 N번(O(N))의 시도(검색)가 필요하다. (평균 N/2번) 하지만 Grover’s algorithm으로는 N−−√번(O(N−−√))이면 검색이 가능하다. Classical algorithm보다 quadratic speedup(2차 속도증가)으로 답을 구할 수 있다. 이 알고리즘은 단순히 데이터베이스에서 특정 데이터를 찾는 것 이상으로 다양한 응용범위를 가질 수 있다.
먼저 간단히 qubit의 개수가 2개인(n = 2) 경우를 살펴보자.
우선 2개의 qubit이 표현할 수 있는 상태는 22=4개이다.
여기서 x=x0인 경우에는 f(x) = 1, x≠x0이면 f(x) = 0인 함수 f:{0,1}2→{0,1}가 있다고 하자. 우리는 input인 x값 4개 중에서 하나의 x0를 찾아야 한다.
초기 두 큐비트 상태는 |0⟩로 준비하고 가장 아래에 있는 qubit은 ancillary qubit(보조 큐비트)로 |1⟩의 상태로 준비한다. 준비된 3개의 qubit에 Hadamard gate를 적용시키고 Oracle이라고 하는 operator를 적용한다. 오라클은 |x⟩|y⟩→|x⟩|y⊕f(x)⟩의 연산을 수행하기 때문에 보조 큐비트가 12√(|0⟩–|1⟩)이라면
O|x⟩12√(|0⟩–|1⟩)→(−1)f(x)|x⟩12√(|0⟩–|1⟩)이 성립한다. (Deutsch’s algorithm 참조)
그로버 알고리즘(Grover’s algorithm)
반응형
그로버 알고리즘
qiskit 문서 ‘Grover’s search with an unknown number of solutions’를 참고하였고 그로버 알고리즘의 통계학적 해석에 대해서는 통계학 교수님께 도움을 받음.
그로버 알고리즘 활용
N개의 정렬되어 있지 않은 항목들 중에서 원하는 특징을 가지고 있는 항목 한개를 탐색해볼것임.
고전적인 연산은 N단계를 거쳐야 하나 그로버 알고리즘을 활용하면 N*(1/2)단계 만에 찾을 수 있음
그로버 알고리즘 문제
이 문서는 ibmq- qiskit textbook을 참고하여 작성하였습니다.
반응형
양자 컴퓨팅 입문 (2) – Grover’s Algorithm
Grover’s Algorithm은 정렬되지 않은 데이터베이스에 있는 $N$개의 항목 중 특정한 조건을 만족하는 항목을 $O(\sqrt{N})$에 찾는 알고리즘입니다.
고전 컴퓨팅에서 이 문제를 해결하려면, 간단하지만 느리게 갈 수밖에 없습니다. 전수 조사(brute force)가 유일한 해결책입니다. 당연히 시간 복잡도는 $O(N)$이며, 랜덤하게 셔플해서 순서를 바꾼다 해도 마찬가지입니다. 그리고 이보다 더 나은 시간복잡도로 찾을 수는 없습니다.
Grover’s Algorithm은 이 시간복잡도를 $O(\sqrt{N})$으로 낮추는데 성공하였고, 이 시간복잡도가 최적이라는 것이 알려져 있습니다. 또다른 유명한 양자 알고리즘인 Shor’s Algorithm과는 달리 알고리즘 자체가 간단하면서도 심도 있기 때문에 이론적으로 탐구해보고자 합니다.
알고리즘
$n$개의 qubit $\left\vert \psi \right>$가 $\left\vert 0 \right>^{\otimes n}$의 상태로 있고, 함수 $f$가 다음과 같이 정의되어 있다고 합시다.
$f(\psi) = \begin{cases} 1 & \text{if } \left\vert \psi \right> \in A \subset {\left\vert 0 \right>,\left\vert 1 \right>}^{\otimes n} \ 0 & \text{otherwise}\end{cases}$
즉 $\psi$가 특정 기저 상태면 (달리 표현해 $A$에 속하면) 1이고, 아니면 0인 함수입니다. 이런 $A$의 예시로는 데이터베이스에서 특정 쿼리의 조건을 만족하는 항목들이나, 암호화 과정에서 후보가 될 수 있는 key의 집합이 있습니다.
$A$의 크기가 $M$이고 $N = 2^n$이라 할 때, Grover’s Algorithm은 $f(\psi) = 1$를 만족하는 $\psi$를 오라클 호출 $\frac{\pi}{4} \sqrt{\frac{N}{M}}$번 후 확률 $1 – \frac{M}{N}$로 찾을 수 있습니다.
알고리즘은 다음과 같습니다.
$\left\vert 0 \right>^{\otimes n}$ (모든 큐빗을 $\left\vert 0 \right>$ 상태로 만든다.) $H^{\otimes n} \left\vert 0\right>^{\otimes n} = \dfrac{1}{\sqrt{2^n}} \sum\limits_{x=0}^{2^n-1}\left\vert x\right> = \left\vert \psi\right>$ (모든 큐빗에 Hadamard operator를 건다.) $[(2 \left\vert \psi \right> \left<\psi\right\vert - I) (-1)^f]^R \left\vert \psi \right> \approx \left\vert \psi’ \right>$ (Grover iteration을 $R \approx \frac{\pi}{4}\sqrt{2^n/M}$ 번 시행한다.) $\psi’$ (관찰한다.)
풀어쓰면 큐빗에 $H$를 전부 건 다음, Grover iteration이라는 과정을 통해 $A$에 속하는 기저들의 진폭을 증가, 나머지는 감소시킵니다. Grover Iteration을 $R$번 반복하면 위의 확률로 $A$에 속하는 기저 상태를 관찰할 수 있습니다.
이 밑에 나오는 설명은 편의상 $M = 1$을 가정합니다. $M > 1$일 때의 증명 및 설명은 참고문헌으로 대체합니다.
Quantum Oracle
$f$는 다음과 같은 quantum oracle $\mathcal{O}$로 해석할 수 있습니다.
$\mathcal{O}\left\vert x \right> \left\vert y \right> = \left\vert x \right> \left\vert y \oplus f(x) \right>$
$\oplus$로 표기할 수 있는 이유는, 양자 컴퓨팅의 CNOT이 고전 컴퓨팅의 XOR에 대응되기 때문입니다. 그럼 Grover’s Algorithm에 필요한 quantum oracle인
$\mathcal{O}\left\vert x \right>\left\vert y \right> \to (-1)^{f(x)} \left\vert x \right>\left\vert y\right>$
은 어떻게 구상해야 할까요? 다양한 방법이 있겠지만 가장 간편하고 널리 알려진 방법 중 하나인 phase kickback trick을 이용할 수 있습니다. $\left\vert y \right> = \left\vert – \right> = \dfrac{\left\vert 0 \right> – \left\vert 1 \right>}{\sqrt{2}}$로 하고 $\mathcal{O}$를 적용하면 놀라운 일이 벌어집니다.
$\begin{aligned} \mathcal{O}\left\vert x \right> \left\vert – \right> &= \dfrac{1}{\sqrt{2}} (\mathcal{O}\left\vert x \right>\left\vert 0 \right> – \mathcal{O}\left\vert x \right>\left\vert 1 \right>) \ &= \dfrac{1}{\sqrt{2}} (\left\vert x \right>\left\vert f(x) \right> – \left\vert x \right>\left\vert 1 \oplus f(x)\right>) \ &= \begin{cases} \frac{1}{\sqrt{2}}(\left\vert x \right>\left\vert 0 \right> – \left\vert x \right>\left\vert 1 \right>) = \left\vert x \right>\left\vert – \right> & f(x) = 0 \ \frac{1}{\sqrt{2}}(\left\vert x \right>\left\vert 1 \right> – \left\vert x \right>\left\vert 0 \right>) = -\left\vert x \right>\left\vert – \right> & f(x) = 1 \end{cases} \ &=(-1)^{f(x)}\left\vert x \right>\left\vert – \right>\end{aligned}$
분명히 $\mathcal{O}\left\vert x \right> \left\vert y \right> = \left\vert x \right> \left\vert y \oplus f(x) \right>$인데도 불구하고 $y$쪽은 그대로인채, $x$만 변한 것을 알 수 있습니다.
$\omega \in A$일 때, 이 과정은 수학적으로 $(I – 2 \left\vert \omega \right> \left<\omega \right\vert)$으로 표현할 수 있습니다. 지금은 $A = {\omega}$를 전제하고 있지만 $M > 1$이 되어도 비슷한 논리를 적용할 수 있습니다.
이런 식으로 특정 기저의 진폭 부호를 뒤집는 방식을 conditional sign flip이라고 합니다.
Diffusion Transform
$(2 \left\vert \psi \right> \left<\psi\right\vert - I)$는 diffusion transform이라 불리는 과정입니다. 수학적으로 $I - 2\mathbf{v}\mathbf{v}^\dagger$는 Householder Transformation인데, Hermitian이고 unitary하면서 기하학적 대칭변환으로 해석할 수 있습니다. 이 과정은 각 기저의 진폭을 평균에 대해 대칭시킵니다. 위에서 $A$에 속한 기저의 진폭이 음수가 되었고, 일반적으로 $A$의 크기가 $N$에 비해 작기 때문에, 평균 진폭값에 비해 큰 차이가 납니다. 이 상태에서 diffusion transform을 진행하면 음수 진폭이 양수가 됨과 동시에 다른 진폭보다 더 큰 값을 가지게 됩니다. 평균에서 더 멀리 떨어져있었기 때문입니다. 관측 확률 비록 계산결과를 직접 쓰진 않았지만, Grover Iteration은 $k^2 + l^2(N-1) = 1$을 만족하는 실수쌍 $(k, l)$을 $(\frac{N-2}{N}k + \frac{2(N-1)}{N}l, \frac{N-2}{N}l - \frac{2}{N}k)$로 변환합니다. 이를 점화식 꼴로 쓰면 $\begin{aligned} k_0 &= l_0 = \frac{1}{\sqrt{N}} \ (k_{j+1}, l_{j+1}) &= \left(\frac{N-2}{N}k_j + \frac{2(N-1)}{N}l_j, \frac{N-2}{N}l_j - \frac{2}{N}k_j\right) \end{aligned}$ 가 됩니다. 놀랍게도 일반항이 기하학적인 꼴로 나옵니다. $\sin^2 \theta = \frac{1}{N}$인 $\theta$를 잡으면 $\begin{aligned} k_j &= \sin((2j+1)\theta) \ l_j &= \frac{1}{\sqrt{N-1}} \cos((2j+1)\theta) \end{aligned}$ 와 같이 나오게 됩니다. $k$가 우리가 원하는 특정 성질이 있는 기저의 확률이므로, $(2m+1)\theta = \pi/2 \implies m = \dfrac{\pi - 2\theta}{4\theta}$가 될 때 관찰 확률이 1이 됩니다. 때문에 $M = \lfloor \pi/{4\theta}\rfloor \approx \lfloor \frac{\pi}{4} \sqrt{N}\rfloor$ 정도 돌리면 충분해보임을 알 수 있고, 논문에 의하면 그렇습니다. 구현체 Grover’s Algorithm의 구현체를 찾아보면 예상외로 간단한 편입니다. 오라클 적용과 diffusion transform의 구현이 간단한 탓입니다. $\left\vert - \right> = HX\left\vert 0 \right>$이기 때문에, 위에서 살펴본 phase kickback trick을 이용하면 오라클 적용 파트는 쉽게 넘어갈 수 있습니다. 다만 diffusion transform은 조금 더 풀어서 설명을 해보겠습니다.
$(2 \left\vert \psi \right> \left<\psi\right\vert - I) = H^{\otimes n} (2 \left\vert 0 \right>^{\otimes n} \left<0\right\vert^{\otimes n} - I) H^{\otimes n}$인지라, $(2 \left\vert 0 \right>^{\otimes n} \left<0\right\vert^{\otimes n} - I)$를 해석해보아야 합니다. 살펴보면 이는 $\left\vert 0 \right>^{\otimes n}$을 제외하고 전부 진폭의 부호를 뒤집는 연산입니다.
$(2 \left\vert 0 \right>^{\otimes n} \left<0\right\vert^{\otimes n} - I)\left\vert x \right> = \begin{cases} 2 \left\vert 0 \right>^{\otimes n} \left<0\right\vert^{\otimes n}\left\vert x \right> – \left\vert x \right> = – \left\vert x \right> & \text{if }\left\vert x \right>
eq \left\vert 0 \right>^{\otimes n} \ 2 \left\vert 0 \right>^{\otimes n} \left<0\right\vert^{\otimes n}\left\vert x \right> – \left\vert x \right> = \left\vert x \right> & \text{if }\left\vert x \right> = \left\vert 0 \right>^{\otimes n}\end{cases} $
$\left<0\right\vert^{\otimes n}\left\vert x \right>$ 가 $\left\vert x \right>
eq \left\vert 0\right>^{\otimes n}$이면 서로 다른 두 기저벡터의 내적이기 때문에 $0$이 됨을 이용합니다. 때문에 부호를 거꾸로 한 $(I – 2\left\vert 0 \right>^{\otimes n} \left<0\right\vert^{\otimes n})$는 $\left\vert 0 \right>^{\otimes n}$의 진폭만 부호를 뒤집는 연산입니다.
큐빗 전체에 $X$연산을 적용하면 $\left\vert 1 \right>^{\otimes n}$만 뒤집는 연산으로 볼 수 있고, 이건 특이한 트릭으로 구현 가능합니다. 첫 $n-1$개의 큐빗을 controlled qubit으로 놓고, 마지막 큐빗을 target qubit으로 두어 $Z$연산을 하면 됩니다. 여기서 $Z$ 연산은 Pauli-Z gate로
\[Z = \begin{bmatrix} 1 & 0 \\ 0 &-1\end{bmatrix}\]
입니다. controlled가 적용되는 첫 $n-1$개의 큐빗은 기저가 $\left\vert 1 \right>^{\otimes n-1}$일 때이며, $Z$ 연산에 의해 target이 $\left\vert 1 \right>$일 때만 부호가 반전됩니다. 그러므로 $\left\vert 1 \right>^{\otimes n}$의 진폭만 부호를 반전시킵니다.
종합하면 Grover’s Algorithm을 구현할 수 있습니다. 구현체는 인터넷에 많이 공개되어 있기 때문에 알고리즘을 잘 이해하지 못했더라도 black-box function처럼 사용할 수 있습니다.
관련 연구
Grover’s Algorithm의 시간복잡도와 시행횟수가 최적이라는 점이 알려져 있기 때문에, 적은 횟수만큼 돌리고 관찰을 한 다음에 그 결과에 따라 추가적으로 몇 번 더 돌리는 전략에 대한 연구도 진행되고 있습니다. $M$의 값을 알고 돌리면 편하겠지만, 모르더라도 $O(\sqrt{N/M})$번 정도 돌려서 원하는 상태를 알아낼 수 있는 접근법이 존재합니다.
이전 글에서도 소개했지만, Grover’s Algorithm을 고전 알고리즘과 결합하여 시간복잡도 향상을 꾀하는 경우가 많습니다.
결론
비록 엄밀한 증명을 다루지는 않았지만 대략적으로 Grover’s Algorithm이 어떻게 동작하고, 구현은 어떻게 되는지를 살펴보았습니다. 이해가 어려울 수 있지만 양자컴퓨팅의 기초와도 같은 알고리즘이고, 유용한 기법도 많이 사용되기에 숙지해두면 좋겠습니다. 다음에는 Microsoft Q#의 syntax를 다루면서 Grover’s Algorithm의 구현체를 살펴보도록 하겠습니다.
참고 문헌
키워드에 대한 정보 그로버 알고리즘
다음은 Bing에서 그로버 알고리즘 주제에 대한 검색 결과입니다. 필요한 경우 더 읽을 수 있습니다.
이 기사는 인터넷의 다양한 출처에서 편집되었습니다. 이 기사가 유용했기를 바랍니다. 이 기사가 유용하다고 생각되면 공유하십시오. 매우 감사합니다!
사람들이 주제에 대해 자주 검색하는 키워드 양자컴퓨터의 기초와 그루버 알고리즘
- quantum computer
- 양자컴퓨터
- 그루버 알고리즘
- 양자회로
- 큐비트
- 게이트
- 논리회로
- 양자컴퓨터 강좌
- 양자컴퓨터강의
- 중첩현상
- 얽힘현상
- quantum computing
- quantum mechanics
- quantum entanglement
- history of quantum physics
- physics
- quantum
- superposition
- interference
- double-slit experiment
- entanglement
- computing
- feynman
- shor's algorithm
- Deutsch
- Deutsch–Jozsa algorithm
- David Deutsch
- Richard Feynman
- Albert Einstein
- EPR
- Bell
양자컴퓨터의 #기초와 #그루버 #알고리즘
YouTube에서 그로버 알고리즘 주제의 다른 동영상 보기
주제에 대한 기사를 시청해 주셔서 감사합니다 양자컴퓨터의 기초와 그루버 알고리즘 | 그로버 알고리즘, 이 기사가 유용하다고 생각되면 공유하십시오, 매우 감사합니다.